Exécuter un modèle instruct 3B avec MLX-Swift dans une app Mac livrée aux utilisateurs
By Stefan Schmitt · 2026-05-29
Brouillon rédigé avec l'IA ; recherche, édition et vérification des faits par moi — comment j'écris.
Le problème
Dans un article précédent, j'ai parlé d'acheminer un modèle de plusieurs Go jusqu'au Mac d'un utilisateur avec Background Assets. Cet article s'arrêtait là où celui-ci commence : le téléchargement se termine, et il vous reste un dossier contenant les poids sur le disque — un fichier .safetensors, un config.json, un tokenizer, un chat template. Maintenant, il faut que ça s'exécute.
Les exemples de MLX-Swift font paraître cette partie triviale. Vous chargez un conteneur de modèle, vous streamez des tokens, vous les affichez. Pour une démo, c'est vraiment aussi simple, et cette facilité est un piège : elle laisse croire que l'exécution du modèle est la partie à laquelle vous n'avez pas à réfléchir.
Narration Room livre un modèle instruct 3B quantifié sur 4 bits — environ 2,75 Go sur disque — comme générateur on-device. Passer de « l'exemple affiche des tokens » à « ça marche sur le Mac d'un inconnu sans me faire honte » m'a pris plus de temps que je ne voudrais l'admettre ; les exemples ne couvrent qu'une petite partie de ce parcours.
Les petits modèles cessent de respecter la structure attendue précisément quand vous avez besoin de JSON strict. La première requête après le lancement est assez lente pour donner l'impression que quelque chose est cassé.
L'app n'a pas une seule façon de générer du texte. Elle en a deux : Apple Foundation Models, qui reste le fallback système sans téléchargement lorsqu'il est disponible, et MLX, qui exécute le modèle 3B téléchargé lorsqu'il est prêt.
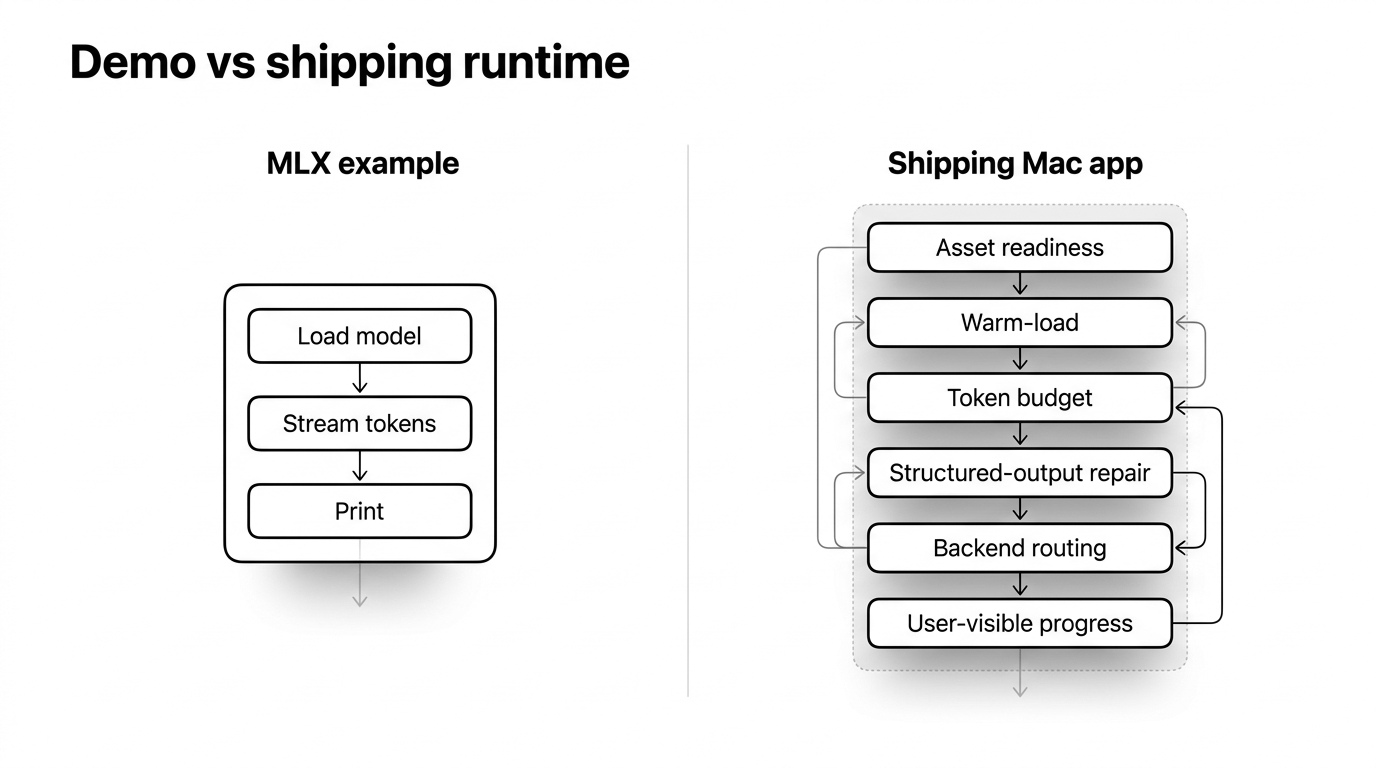
Ce sont des notes de terrain de cette période. J'écris l'article sur le runtime que j'aurais voulu avoir en commençant.
Le modèle mental que la documentation passe sous silence
C'est l'architecture qui m'a posé problème, alors voici le modèle que j'aurais aimé avoir dès le premier jour.
Votre binaire reste petit ; votre mémoire résidente, non. C'est la même leçon que côté livraison, vue depuis l'autre côté. Les poids ne sont pas dans le bundle de votre app ; Background Assets les télécharge séparément et les stocke en dehors de votre sandbox.
Ce qui grossit, c'est la RAM au moment de l'inférence, une fois les poids sur le GPU. Pour le générateur, cela représente environ 2,6 Go de poids, plus un KV cache qui croît avec la fenêtre de contexte, soit environ un gigaoctet de plus à 8K de contexte.
Un petit chiffre de téléchargement et un grand chiffre de mémoire résidente coexistent. Vous devriez indiquer les deux, car le coût disque est celui que les utilisateurs remarquent et le coût mémoire est celui qui provoque les plantages.
J'ai limité l'actor de chargement à un seul modèle. Dans Narration Room, l'objet qui charge les poids est un actor autour du ModelContainer de MLX-Swift. Je l'ai volontairement conçu pour ne garder qu'un seul modèle chargé à la fois.
Le commentaire de documentation est là pour rendre cette règle visible : « Ne gère qu'un seul modèle chargé à la fois. Appeler warmLoad avec un répertoire différent décharge d'abord le modèle courant. » C'est de l'architecture propre à l'app, pas une règle imposée par MLX-Swift.
La conséquence est simple : cet objet de chargement ne se partage pas à la légère. Si vous lui demandez de charger un second modèle, il décharge le premier ; si vous lui demandez ensuite de revenir au premier modèle, il doit le recharger entièrement. Pour garder plusieurs modèles résidents, utilisez plusieurs objets de chargement et dimensionnez votre budget mémoire en conséquence.
J'ai confié le chat template à une seule couche. Dans Narration Room, le code de la fonctionnalité ne construit pas la chaîne de prompt finale. Il envoie à la couche qui exécute le modèle une liste de messages, chacun avec un rôle comme system, user ou assistant.
Cette couche est le seul endroit qui transforme ces messages en prompt propre au modèle, avec le chat template livré avec le modèle. Ce point de formatage centralisé compte parce que le comptage de tokens et la génération doivent formater la conversation de la même façon ; sinon mon calcul de budget est silencieusement faux.
Les deux chemins appellent applyChatTemplate sur le modèle : le comptage de tokens et la génération utilisent donc la même chaîne de prompt finale, pas seulement le même texte brut des messages.
Dans mon app, deux chemins de génération coexistent. Le framework Foundation Models d'Apple est le chemin système sans téléchargement lorsque SystemLanguageModel signale sa disponibilité. Le chemin MLX est l'option plus lourde, que vous contrôlez, et qui coûte 2,75 Go avec un chargement de modèle.
Dans Narration Room, les deux sont disponibles en même temps, et l'app choisit à chaque requête lequel utiliser. Le jour où j'ai cessé de penser « j'ai un LLM » pour penser « j'ai deux façons de générer du texte, avec des coûts et des modes d'échec différents », le reste de la conception s'est mis en place.
Les pièges que vous rencontrez vraiment à l'exécution
1. La sortie structurée échoue au premier essai — et réessayer ne vous sauvera pas
C'est celui qui m'a coûté le plus, et c'est la chose la plus importante de cet article.
Je demande du JSON au modèle — un schéma pour le script de narration — et la réponse échoue à la validation :
Structured output validation failed on first attempt: The operation couldn't be
completed. (MLXStructuredOutputError error 1.)
« Error 1 » a l'air mystérieux, mais cela signifie simplement decodingFailed : Swift affiche le cas de l'énumération par son numéro (invalidJSON est le cas 0, decodingFailed le cas 1). La partie intéressante est ce que le modèle a réellement produit. Un modèle 3B, à qui l'on demande du JSON propre, renvoie ceci :
{
"speakers": [],
"lines": [
{"text": "A wide range of platforms and computer systems are used in this environment."},
{"text": "Installation requires copying and pasting a text block into the agent's input."},
{"text": "Yet, the agent's dependency on correct input remains an implicit assumption."
]
}
Deux défauts, et les petits modèles font les deux en permanence. D'abord, il a enveloppé l'ensemble dans un bloc Markdown json, malgré un prompt qui disait « no markdown fences ».
Ensuite, regardez la dernière ligne : il a épuisé son budget de sortie en plein milieu de la structure, si bien que le dernier élément du tableau n'a jamais son } de fermeture avant l'arrivée du ]. Ce n'est pas du JSON valide, et le décodeur le rejette : « The data couldn't be read because it isn't in the correct format. »
La réponse entière, 853 caractères et sept lignes, est jetée pour une seule accolade manquante.
Voici la partie honnête. Le correctif évident était déjà dans le code, et il n'a pas marché. J'avais déjà une seule nouvelle tentative qui relançait la génération avec une instruction plus stricte en cas d'échec de validation :
do {
return try validateResponse(response, structuredOutput: structuredOutput)
} catch is MLXStructuredOutputError {
// The model didn't follow the schema. Retry once, stricter.
let retrySystem = (wrappedSystem ?? "") + "\nRespond with valid JSON only. No other text."
let retryRequest = makeRequest(prompt: wrappedPrompt, systemInstruction: retrySystem)
return try validateResponse(try await collect(request: retryRequest),
structuredOutput: structuredOutput)
}
Le prompt système disait déjà « Output ONLY valid JSON ». La nouvelle tentative l'a redit, plus fort. Le modèle a échoué de la même manière la seconde fois, parce que l'échec n'est pas de la désobéissance. C'est un modèle 3B à court de tokens, et répéter l'instruction plus fort n'ajoute pas de tokens. Une nouvelle tentative vous coûte une génération complète de plus et vous ramène au même point.
Ce qui a marché, c'est de cesser de demander au modèle d'être parfait et de nettoyer le JSON invalide avant que le décodeur ne le voie. Aucun LLM n'intervient. Si le modèle s'arrête au milieu du dernier élément du tableau, la réparation supprime cet élément inachevé ou referme les accolades manquantes. Dans l'exemple ci-dessus, le correctif consiste simplement à ajouter le } manquant avant le ] du tableau.
Cette réparation s'exécute avant le décodage, et aussi sur la sortie de la nouvelle tentative. La nouvelle tentative existe toujours, mais elle n'est plus la seule chose entre une petite erreur de formatage et une requête en échec.
L'ordre compte. Ce qu'il me faut, c'est l'objet JSON entier, pas n'importe quel fragment JSON valide à l'intérieur. La réparation essaie donc d'abord de préserver cet objet en refermant les accolades laissées ouvertes par la troncature. Seulement si elle n'y arrive pas, j'utilise le fallback plus permissif, qui extrait un fragment complet plus petit depuis le texte. La règle importante est de ne pas laisser un fragment partiel passer pour une réponse complète.
Je vais être honnête : c'est une réparation manuelle du texte brut produit par le modèle, et ce n'est pas une abstraction propre. Deux choses me permettent de l'assumer malgré tout. La réparation ne se déclenche que lorsque le parsing normal échoue ; une réponse correcte ne passe jamais par là. Et contrairement à la nouvelle tentative, elle ne relance jamais le modèle : aucune seconde génération à payer, et la même sortie invalide est toujours réparée de la même façon.
Le risque est clair : la réparation ne sait gérer que les formes d'échec que j'ai déjà vues. Je m'appuie sur des fixtures construites à partir de ces échecs précis, de sorte qu'une forme connue ne peut pas régresser en silence — mais une forme inédite passerait quand même au travers. La vérité plus profonde, c'est qu'un modèle 3B ne produit pas de JSON de manière fiable.
Si vous avez besoin d'une sortie structurée venant d'un tel modèle, réparez-la au moment où le texte brut du modèle devient des données typées, au lieu de faire confiance au premier essai : réparer, puis réessayer, puis échouer explicitement, dans cet ordre.
2. Le chargement du modèle est un état à part entière
Charger 2,75 Go de poids en mémoire prend un temps réellement perceptible. Si vous traitez ce temps comme invisible, l'utilisateur a l'impression que sa première interaction avec la fonctionnalité est lente, et il en blâme la fonctionnalité, pas le chargement.
J'ai donc fait du chargement du modèle une étape à part entière. L'actor qui charge le modèle a une méthode warmLoad, et Narration Room l'appelle avant d'autoriser une requête à utiliser MLX. L'appel est chronométré : si le chargement prend plus de 100 ms, il est consigné dans les logs.
Un chargement en arrière-plan démarre avant la première utilisation ; les poids sont donc souvent déjà résidents au moment où l'utilisateur déclenche la fonctionnalité.
3. Décidez s'il faut tenter MLX — avant de le tenter
Dans Narration Room, tenter ou non le modèle MLX est une décision par machine, qui dépend de la RAM disponible : la fenêtre de contexte que je peux autoriser dépend de la mémoire de la machine, parce que le KV cache croît avec elle.
static func defaultContextCap(ramGB: Int) -> Int {
switch ramGB {
case ..<16: return 8_192
case ..<24: return 16_384
case ..<32: return 32_768
// …rising with available RAM…
default: return 262_144
}
}
Avec ma politique par défaut, un Mac de 16 Go obtient un contexte de 16K ; une machine avec davantage de RAM obtient les 256K complets du modèle. À partir de ce plafond, je réserve une marge de sortie, puis je déduis la quantité d'entrée que je peux accepter sans risque.
Ce plafond est un choix de performance autant qu'un choix mémoire. Augmenter la fenêtre maximale ne ralentit pas forcément toutes les requêtes, mais une requête qui utilise réellement davantage de contexte demande plus de travail : des prompts plus longs signifient plus de prefill, et un historique actif plus long rend le décodage plus lourd.
Si l'entrée est trop grande, la génération ne démarre jamais. L'app lève une MLXInputOverflowError et affiche un vrai message au lieu de lancer un travail qu'elle ne peut pas terminer : « Votre contenu source est trop long pour un traitement on-device. Essayez de le raccourcir. »
Le compromis est explicite, et c'est le bon ici. Une fois la marge de sortie réservée, ce contexte de 16K laisse à un Mac de 16 Go environ 8K tokens pour l'entrée, si bien que certaines entrées longues sont rejetées ou découpées au lieu d'être exécutées. Je préfère le dire d'emblée plutôt que de laisser un utilisateur découvrir son plafond de RAM par un plantage faute de mémoire.
Foundation Models ou MLX — et comment je choisis entre les deux
Les deux chemins de génération sont bons à des choses différentes, et la comparaison est la véritable décision.
Apple Foundation Models est le chemin système : pas de téléchargement de modèle séparé, pas de facture API par requête, et — la partie à laquelle je tiens le plus lorsqu'il est disponible — une sortie structurée vraiment fiable via la macro @Generable. Le schéma est imposé par le runtime d'Apple au lieu de dépendre d'un prompt.
Vous vérifiez SystemLanguageModel.default.availability == .available, vous ouvrez une LanguageModelSession, et c'est parti. Les coûts : vous ne contrôlez ni le modèle ni ses guardrails, l'appel de disponibilité peut tout simplement répondre indisponible, et la fenêtre de contexte est petite, le budget on-device étant plafonné autour de 4 096 tokens.
Le chemin MLX présente les compromis inverses. Dans Narration Room, je contrôle le modèle, et je laisse la fenêtre de contexte passer de 8K à 256K selon la RAM de la machine. Je paie cela par un téléchargement de 2,75 Go, le chargement du modèle, un budget mémoire que je gère moi-même, et une sortie structurée qui, comme le piège 1 l'a montré douloureusement, est du JSON libre produit par prompt engineering que je dois valider et réparer.
Utilisez Foundation pour les tâches courtes structurées par un schéma, là où sa fiabilité et son empreinte nulle l'emportent. Réservez MLX quand vous avez besoin d'un contexte plus grand ou de plus de contrôle, et que vous êtes prêt à assumer le coût d'exécution.
Dans Narration Room, le choix entre les deux se fait en deux phases, et les phases ont des règles d'échec délibérément différentes :
if useMLX {
// Phase 1 — setup. Environmental failure (model files missing, load fails) falls back to Foundation.
do { try await ensureMLXReady() }
catch { return try await foundation.generateText(/* … */) }
// Phase 2 — generation. The model is confirmed ready. No silent fallback; errors propagate.
return try await mlx.generateText(/* … */)
}
return try await foundation.generateText(/* … */)
C'est pour cela que j'ai divisé le choix en deux phases. Les échecs de setup sont environnementaux : les fichiers du modèle téléchargé ne sont pas là, ou le chargement échoue. Se rabattre sur Foundation est la bonne réponse, et elle reste invisible pour l'utilisateur.
Les échecs de génération sont différents. Une fois le modèle confirmé chargé, les erreurs se propagent. Changer silencieusement de chemin de génération en plein milieu masquerait de vrais bugs et donnerait à l'utilisateur une sortie incohérente, sans lui dire que le chemin a changé. Si le fallback vers Foundation échoue lui aussi, cela remonte comme une erreur distincte plutôt que générique. Le fallback doit se faire à l'entrée, jamais à la sortie.
Liste de contrôle avant production
Ce que je vérifie avant de faire confiance à un LLM on-device dans un build :
- Charger le modèle avant la première utilisation, et montrer ce chargement comme une étape à part — ne le laissez pas se faire passer pour une inférence lente.
- Pour l'objet de chargement que j'utilise, qui ne garde qu'un modèle à la fois, gardez un objet par modèle résident ; lui demander de charger un second modèle décharge le premier.
- Validez l'entrée par rapport au budget lié au palier de RAM et rejetez tôt les prompts trop volumineux, avec un message qui propose une vraie alternative.
- Sortie structurée venant d'un petit modèle : réparez de façon déterministe, puis réessayez une fois, puis échouez explicitement. Ne faites jamais confiance au premier essai.
- La phase 1 (setup) peut se rabattre sur Foundation ; la phase 2 (génération) ne se rabat pas silencieusement.
- Indiquez à la fois la taille sur disque et le pic de mémoire dans votre texte destiné aux utilisateurs.
- Comptez les tokens via le même chat template que votre chemin de génération, pas avec une heuristique basée sur les caractères.
Ce que la documentation ne couvre pas encore
Je n'aurais pas écrit ceci si les lacunes ne m'avaient pas coûté de vraies journées.
- Les exemples de MLX-Swift s'arrêtent au « hello world ». Tout ce qui vient après « afficher les tokens » — le chargement explicite du modèle, les budgets selon le palier de RAM, le choix entre chemins de génération, la récupération d'une sortie structurée — vous l'assemblez vous-même.
- L'API de la bibliothèque bouge. Une montée de version a changé la façon de charger un modèle : la version récente de MLX-Swift LM attend qu'on lui passe un tokenizer loader à côté du répertoire, et l'ancien appel à argument unique a été supprimé. Vous l'apprenez quand ça casse, pas en lisant.
- Personne ne vous dit qu'avec un petit modèle, une nouvelle tentative ne suffit pas pour la sortie structurée : il faut aussi une réparation déterministe. La nouvelle tentative est l'idée évidente, et c'est celle qui ne marche pas.
Le framework est bon. Le chemin de l'exemple à la production est largement non documenté, alors j'ai écrit la partie que j'aurais aimé trouver en commençant.
La suite
Si ce genre de notes de terrain vous est utile, la newsletter est le meilleur moyen de ne pas manquer la suivante.