Ein 3B-Instruct-Modell mit MLX-Swift in einer ausgelieferten Mac-App betreiben
By Stefan Schmitt · 2026-05-29
Mit KI entworfen; von mir recherchiert, redigiert und auf Fakten geprüft — wie ich schreibe.
Das Problem
In einem früheren Artikel habe ich beschrieben, wie man ein mehrere GB großes Modell auf den Mac eines Nutzers bekommt — mit Background Assets. Jener Artikel endete dort, wo dieser beginnt: Der Download ist fertig, und übrig bleibt ein Ordner mit Gewichten auf der Festplatte — eine .safetensors-Datei, eine config.json, ein Tokenizer, ein Chat-Template. Jetzt muss das Ganze auch laufen.
Die Beispiele von MLX-Swift lassen diesen Teil trivial wirken. Sie laden einen Modell-Container, streamen Tokens, geben sie aus. Für eine Demo ist es wirklich so einfach, und diese Einfachheit ist eine Falle: Sie weckt die Erwartung, dass das Ausführen des Modells der Teil ist, über den man nicht nachdenken muss.
Narration Room liefert ein auf 4 Bit quantisiertes 3B-Instruct-Modell aus — rund 2,75 GB auf der Festplatte — als On-Device-Generator. Der Weg von „das Beispiel gibt Tokens aus“ zu „das funktioniert auf dem Mac eines Fremden, ohne mich zu blamieren“ hat länger gedauert, als ich zugeben möchte; die Beispiele decken nur einen kleinen Teil dieses Wegs ab.
Kleine Modelle verlieren genau dann die Struktur, wenn Sie striktes JSON brauchen. Die erste Anfrage nach dem Start ist so langsam, dass es wie ein Defekt wirkt.
Die App hat nicht nur einen Weg, Text zu generieren. Sie hat zwei: Apple Foundation Models, das der System-Fallback ohne Download ist, wenn es verfügbar ist, und MLX, das das heruntergeladene 3B-Modell ausführt, sobald es bereit ist.
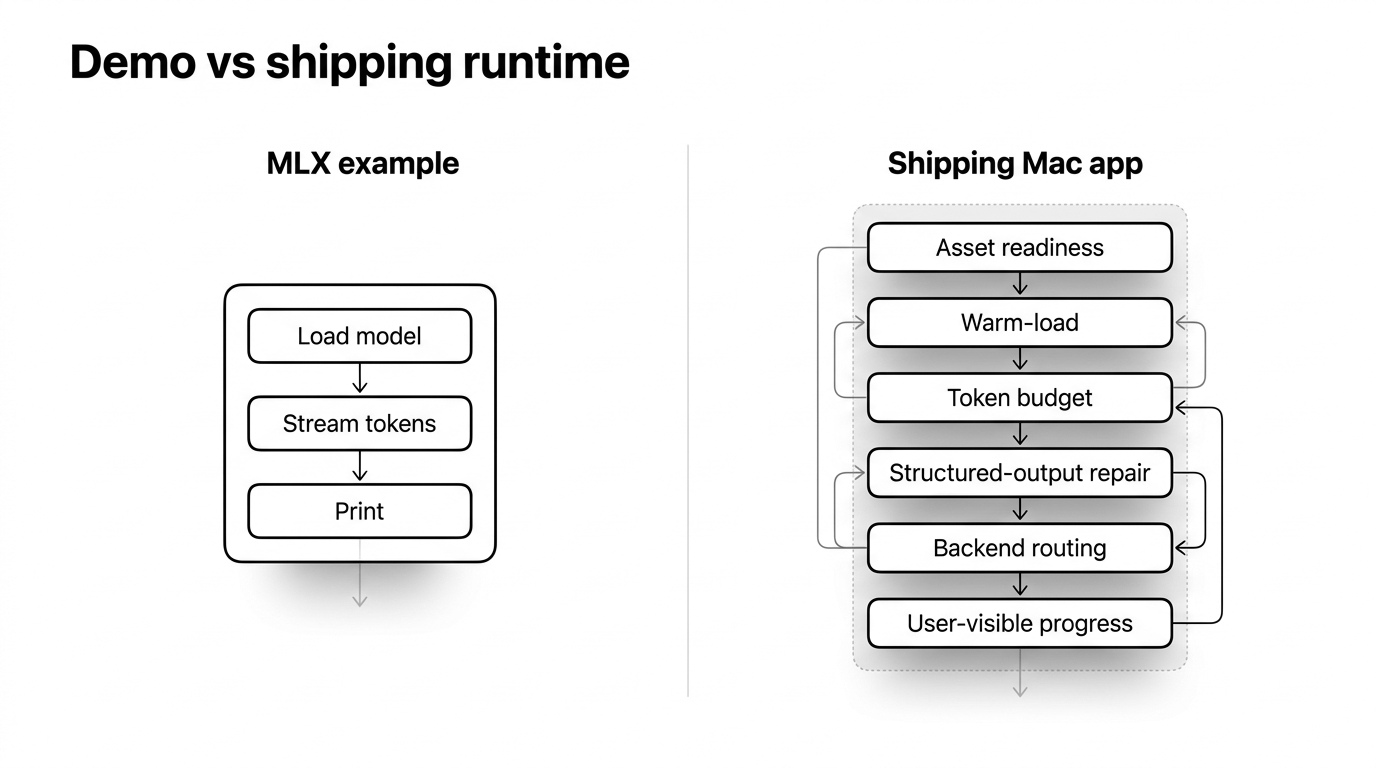
Das sind Praxisnotizen aus dieser Zeit. Ich schreibe genau den Runtime-Artikel, der mir am Anfang selbst gefehlt hat.
Wie das Ganze zusammenhängt — und darüber schweigt die Dokumentation
Die Architektur war der Teil, an dem ich hängen blieb — deshalb zeige ich hier, wie ich sie am ersten Tag gern verstanden hätte.
Ihr Binary bleibt klein; Ihr residenter Speicher nicht. Dieselbe Lektion wie schon beim Download des Modells, nur vom anderen Ende gesehen. Die Gewichte stecken nicht in Ihrem App-Bundle; Background Assets lädt sie separat herunter und legt sie außerhalb Ihrer Sandbox ab.
Was wächst, ist der RAM zur Inferenzzeit, sobald die Gewichte auf der GPU sind. Beim Generator sind das rund 2,6 GB Gewichte plus ein KV-Cache, der mit dem Kontextfenster wächst, bei 8K Kontext noch einmal etwa ein Gigabyte.
Am Ende stehen zwei verschiedene Werte nebeneinander: eine kleinere Größe auf der Platte und ein deutlich größerer RAM-Bedarf zur Laufzeit. Sie sollten beide nennen, denn den Download bemerken Nutzer sofort, und der Speicherbedarf zur Laufzeit ist der Teil, der Abstürze verursachen kann.
Ich habe den Modelllade-Actor jeweils nur ein Modell halten lassen. In Narration Room ist das Objekt, das die Gewichte lädt, ein actor um MLX-Swifts ModelContainer. Ich habe diesen Actor bewusst so gebaut, dass er immer nur ein geladenes Modell hält.
Der Doc-Kommentar macht diese Regel sichtbar: „Verwaltet immer nur ein geladenes Modell. Ein Aufruf von warmLoad mit einem anderen Verzeichnis entlädt zuerst das aktuelle Modell.“ Das ist App-Architektur, keine MLX-Swift-Regel.
Die Konsequenz ist einfach: Dieses Modelllade-Objekt lässt sich nicht einfach so weiterreichen. Lädt dasselbe Objekt ein zweites Modell, wird das erste entladen; brauchen Sie es später wieder, muss das Objekt es vollständig neu laden. Wollen Sie mehrere Modelle gleichzeitig resident halten, verwenden Sie pro Modell ein eigenes Modelllade-Objekt — und planen Sie den Speicher entsprechend ein.
Ich lasse eine einzige Schicht das Chat-Template anwenden. In Narration Room setzt der Code eines Features den endgültigen Prompt-String nicht selbst zusammen. Er schickt eine Liste von Nachrichten an die Schicht, die das Modell ausführt. Jede Nachricht hat eine Rolle wie system, user oder assistant.
Nur diese Schicht setzt aus den Nachrichten den modellspezifischen Prompt zusammen, und zwar mit dem Chat-Template, das zusammen mit dem Modell ausgeliefert wird. Dieser zentrale Formatierungspunkt ist wichtig: Token-Zählung und Generierung müssen die Nachrichten genau gleich formatieren, sonst rechne ich das Token-Budget unbemerkt falsch.
Beide Pfade rufen applyChatTemplate des Modells auf. Damit sehen Token-Zählung und Generierung denselben finalen Prompt-String und nicht nur denselben rohen Nachrichtentext.
In meiner App existieren zwei Modellwege nebeneinander. Apples Framework Foundation Models ist der Systemweg ohne Download, wenn SystemLanguageModel Verfügbarkeit meldet. Der MLX-Weg ist die größere Option, die Sie selbst kontrollieren und die 2,75 GB sowie einen Ladevorgang kostet.
In Narration Room sind beide gleichzeitig verfügbar, und die App entscheidet pro Anfrage, welcher läuft. Für mich wurde der Rest der Architektur erst klar, als ich nicht mehr von „einem LLM“ ausging, sondern von zwei Wegen, Text zu generieren, mit jeweils eigenen Kosten und Fehlermodi.
Die Stolperfallen, die zur Laufzeit wirklich auftauchen
1. Strukturierte Ausgabe scheitert beim ersten Versuch — und ein zweiter Versuch hilft nicht
Das war der Punkt, an dem ich die meiste Zeit verloren habe, und er ist der wichtigste in diesem Artikel.
Ich bitte das Modell um JSON — ein Schema für das Narrations-Skript — und zurück kommt etwas, das die Schema-Prüfung nicht besteht:
Structured output validation failed on first attempt: The operation couldn't be
completed. (MLXStructuredOutputError error 1.)
„Error 1“ klingt rätselhaft, bedeutet hier aber nur decodingFailed: Swift gibt den Enum-Fall als Nummer aus (invalidJSON ist Fall 0, decodingFailed Fall 1). Interessant ist, was das Modell tatsächlich produziert hat. Ein Modell mit 3 Milliarden Parametern, das um sauberes JSON gebeten wird, liefert dies:
{
"speakers": [],
"lines": [
{"text": "A wide range of platforms and computer systems are used in this environment."},
{"text": "Installation requires copying and pasting a text block into the agent's input."},
{"text": "Yet, the agent's dependency on correct input remains an implicit assumption."
]
}
Zwei Defekte, und kleine Modelle begehen beide ständig. Erstens hat es die gesamte Ausgabe in einen Markdown-Codeblock mit json-Label gepackt, obwohl der Prompt „no markdown fences“ sagte.
Zweitens, sehen Sie sich die letzte Zeile an: Mitten in der Struktur ist dem Modell das Ausgabebudget ausgegangen, sodass das letzte Array-Element nie sein schließendes } bekommt, bevor das ] kommt. Das ist kein gültiges JSON, und der Decoder weist es zurück: „The data couldn't be read because it isn't in the correct format.“
Die ganze Antwort, 853 Zeichen und sieben Zeilen, wird wegen einer einzigen fehlenden geschweiften Klammer verworfen.
Jetzt der ehrliche Teil. Der naheliegende Fix war bereits im Code, und er hat nicht funktioniert. Ich hatte bereits einen einmaligen erneuten Versuch, der die Anfrage mit einer strengeren Anweisung neu stellt, wenn die Schema-Prüfung fehlschlägt:
do {
return try validateResponse(response, structuredOutput: structuredOutput)
} catch is MLXStructuredOutputError {
// The model didn't follow the schema. Retry once, stricter.
let retrySystem = (wrappedSystem ?? "") + "\nRespond with valid JSON only. No other text."
let retryRequest = makeRequest(prompt: wrappedPrompt, systemInstruction: retrySystem)
return try validateResponse(try await collect(request: retryRequest),
structuredOutput: structuredOutput)
}
Der System-Prompt sagte bereits „Output ONLY valid JSON“. Der erneute Versuch sagte es noch einmal, nur strenger. Das Modell scheiterte beim zweiten Mal auf dieselbe Weise, nicht weil es die Anweisung absichtlich ignoriert hatte, sondern weil ihm die Tokens ausgegangen waren. Eine strengere Formulierung schafft keine zusätzlichen Tokens. Ein erneuter Versuch kostet Sie eine weitere vollständige Generierung und bringt Sie an denselben Punkt zurück.
Funktioniert hat am Ende etwas anderes: Ich verlasse mich nicht darauf, dass das Modell perfektes JSON liefert. Stattdessen bereinige ich das kaputte JSON, bevor der Decoder es sieht. Dabei kommt kein LLM zum Einsatz. Wenn das Modell mitten im letzten Array-Element stoppt, verwirft mein Code dieses unfertige Element oder ergänzt die fehlenden Klammern. Im Fehler oben besteht der Fix schlicht darin, das fehlende } vor dem ] des Arrays einzufügen.
Diese Reparatur läuft vor dem Decoding; ich wende sie auch auf die Ausgabe des erneuten Versuchs an. Der erneute Versuch bleibt bestehen, aber er ist nicht mehr der einzige Schritt zwischen einem kleinen Formatierungsfehler und einer fehlgeschlagenen Anfrage.
Die Reihenfolge zählt. Was ich brauche, ist das ganze JSON-Objekt, nicht irgendein gültiges JSON-Fragment aus der Modellantwort. Die Reparatur versucht deshalb zuerst, dieses Objekt zu erhalten, indem sie die Klammern schließt, die durch das Abschneiden offen geblieben sind. Erst wenn das nicht klappt, nutze ich den lockereren Fallback: Er extrahiert ein kleineres, vollständiges Fragment aus dem Text. Wichtig ist, dass ein Teilfragment nicht als vollständige Antwort durchgeht.
Ehrlich gesagt ist das eine manuelle Reparatur von rohem Modelltext, keine saubere Abstraktion. Zwei Dinge machen sie für mich trotzdem vertretbar. Sie greift nur, wenn das normale Parsen fehlschlägt; eine saubere Antwort kommt also nie in ihre Nähe. Und anders als der erneute Versuch ruft sie nie das Modell erneut auf: Es fällt keine zweite Generierung an, und dieselbe kaputte Ausgabe wird immer auf dieselbe Weise repariert.
Das Risiko ist klar: Die Reparatur beherrscht nur Fehlerformen, die ich bereits gesehen habe. Ich stütze sie auf Fixtures, die aus genau diesen Fehlern abgeleitet sind. Dadurch wird eine bekannte Form nicht stillschweigend wieder zum Fehler, während eine völlig neue Form trotzdem durchkäme. Im Kern heißt das: Ein Modell mit 3 Milliarden Parametern ist kein zuverlässiger JSON-Generator.
Wenn Sie von einem solchen Modell strukturierte Ausgabe brauchen, reparieren Sie den rohen Modelltext, bevor daraus typisierte Daten werden. Vertrauen Sie nicht auf den ersten Versuch. Die Reihenfolge ist: reparieren, dann einmal erneut versuchen, dann mit einem klaren Fehler abbrechen.
2. Das Laden des Modells ist ein eigener Schritt
2,75 GB Gewichte in den Speicher zu laden, dauert mehrere spürbare Sekunden. Passiert das erst bei der ersten Nutzeranfrage, wirkt die Funktion langsam, noch bevor die Generierung wirklich begonnen hat. Wenn Sie diese Zeit nicht als eigenen Schritt behandeln, fühlt sich die erste Interaktion mit der Funktion langsam an — und das Problem wirkt wie langsame Generierung, nicht wie ein Ladevorgang.
Dafür hat der Modelllade-Actor eine warmLoad-Methode, die Narration Room aufruft, bevor eine Anfrage MLX verwenden darf. Die Dauer des Aufrufs wird gemessen, damit ein langsames Laden in den Logs auftaucht — alles über 100 ms wird festgehalten.
Ein Ladevorgang im Hintergrund läuft schon vor der ersten Nutzung, sodass die Gewichte oft bereits im Speicher liegen, wenn der Nutzer die Funktion auslöst.
3. Vor dem Start entscheiden, ob MLX infrage kommt
In Narration Room entscheidet die App pro Maschine, ob sie das MLX-Modell überhaupt nutzt. Die Entscheidung hängt vom RAM ab: Je mehr Speicher der Nutzer hat, desto größer kann das Kontextfenster sein, weil der KV-Cache mit diesem Fenster wächst.
static func defaultContextCap(ramGB: Int) -> Int {
switch ramGB {
case ..<16: return 8_192
case ..<24: return 16_384
case ..<32: return 32_768
// …rising with available RAM…
default: return 262_144
}
}
Nach meiner Standard-Policy bekommt ein Mac mit 16 GB 16K Kontext; ein Mac mit viel RAM bekommt die vollen 256K des Modells. Davon halte ich zuerst Platz für die Ausgabe frei. Die übrigen Tokens kann ich für die Eingabe verwenden.
Dieses Limit betrifft nicht nur den Speicher, sondern auch die Performance. Ein größeres Kontextfenster macht nicht von sich aus jede Anfrage langsam. Teuer wird es erst, wenn eine Anfrage dieses Fenster tatsächlich stärker ausnutzt: Längere Prompts bedeuten mehr Prefill, und eine längere History macht das Decoding aufwändiger.
Wenn die Eingabe zu groß ist, startet die Generierung gar nicht. Die App löst einen MLXInputOverflowError aus und zeigt eine klare Meldung, statt eine Anfrage zu starten, die nicht fertig werden kann: „Ihr Ausgangsmaterial ist zu lang für die Verarbeitung auf dem Gerät. Kürzen Sie es“.
Der Kompromiss ist explizit, und er ist hier der richtige. Sobald die Ausgabe-Reserve abgezogen ist, lässt dieser 16K-Kontext einem 16-GB-Mac noch etwa 8K Tokens für die Eingabe. Manche langen Eingaben werden deshalb abgewiesen oder in kleinere Teile zerlegt, statt als eine große Anfrage zu laufen. Ich will diese Grenze vorher klar benennen. Sie sollte nicht erst durch einen OOM-Crash auffallen.
Foundation Models oder MLX — und wie ich zwischen ihnen wähle
Die beiden Modellwege haben unterschiedliche Stärken. Die eigentliche Entscheidung ist, welche Kompromisse Sie für eine konkrete Anfrage akzeptieren wollen.
Apple Foundation Models ist der Systemweg: kein separater Modell-Download, keine API-Rechnung pro Anfrage, und — der Teil, den ich am meisten schätze, wenn es verfügbar ist — wirklich zuverlässige strukturierte Ausgabe über das @Generable-Makro. Apples Runtime erzwingt das Schema; man muss also nicht darauf hoffen, dass der Prompt sauber genug formuliert ist.
Sie prüfen SystemLanguageModel.default.availability == .available, öffnen eine LanguageModelSession, und los geht's. Der Preis dafür: Sie kontrollieren weder das Modell noch seine Guardrails. Außerdem kann das Modell schlicht nicht verfügbar sein. Und das Kontextfenster ist klein; das On-Device-Budget liegt bei etwa 4.096 Tokens.
Der MLX-Weg bringt die genau umgekehrten Kompromisse mit. In Narration Room kontrolliere ich das Modell, und ich lasse das Kontextfenster von 8K bis 256K mit dem RAM des Nutzers skalieren. Dafür nehme ich einen 2,75-GB-Download in Kauf, lade das Modell selbst und verwalte das Speicherbudget selbst. Auch die strukturierte Ausgabe liegt bei mir: Das Modell erzeugt per Prompt JSON in freier Form, und wie Stolperfalle 1 gezeigt hat, muss ich diese Ausgabe prüfen und reparieren.
Nutzen Sie Foundation für kurze, schemagebundene Aufgaben, wo seine Zuverlässigkeit und sein minimaler Ressourcenbedarf den Ausschlag geben. Greifen Sie zu MLX, wenn Sie das größere Kontextfenster oder die Kontrolle brauchen und bereit sind, die Laufzeitkosten zu tragen.
In Narration Room entscheidet die App in zwei Phasen zwischen den beiden Wegen. Jede Phase behandelt Fehler bewusst anders:
if useMLX {
// Phase 1 — setup. Environmental failure (model files missing, load fails) falls back to Foundation.
do { try await ensureMLXReady() }
catch { return try await foundation.generateText(/* … */) }
// Phase 2 — generation. The model is confirmed ready. No silent fallback; errors propagate.
return try await mlx.generateText(/* … */)
}
return try await foundation.generateText(/* … */)
Setup-Fehler sind umgebungsbedingt: Die heruntergeladenen Modelldateien sind nicht da, oder das Laden hat nicht geklappt. In diesem Fall ist es richtig, im Hintergrund auf Foundation auszuweichen.
Generierungs-Fehler sind anders. Sobald klar ist, dass das Modell geladen ist, werden Fehler weitergereicht. Den Modellweg mitten in der Funktion stillschweigend zu wechseln, würde echte Bugs verbergen und dem Nutzer inkonsistente Ausgaben liefern, ohne ein Signal, dass sich etwas geändert hat. Schlägt der Fallback auf Foundation ebenfalls fehl, meldet die App diesen Fehler separat, statt alles in einen generischen Fehler zu werfen. Weichen Sie beim Setup aus, aber nicht mehr nach Beginn der Generierung.
Produktions-Checkliste
Was ich prüfe, bevor ich einem On-Device-LLM in einem Build vertraue:
- Laden Sie das Modell vor der ersten Nutzung, und zeigen Sie diesen Ladevorgang als eigenen Schritt — lassen Sie ihn nicht als langsame Inferenz erscheinen.
- Wenn mehrere Modelle gleichzeitig im Speicher bleiben sollen, verwenden Sie mehrere Modelllade-Objekte. Dasselbe Objekt mit einem zweiten Modell zu laden, verdrängt das erste.
- Validieren Sie die Eingabe anhand des RAM-gestaffelten Budgets und weisen Sie zu große Prompts früh ab, mit einer Meldung, die eine echte Alternative anbietet.
- Bei strukturierter Ausgabe aus einem kleinen Modell: Reparieren Sie deterministisch, versuchen Sie es dann einmal erneut, und brechen Sie danach mit einem klaren Fehler ab. Vertrauen Sie nie dem ersten Versuch.
- Phase eins (Setup) darf auf Foundation zurückfallen; Phase zwei (Generierung) fällt nicht stillschweigend zurück.
- Nennen Sie sowohl die Größe auf der Festplatte als auch den Speicher-Spitzenwert in dem Text, den Nutzer sehen.
- Verwenden Sie beim Token-Zählen dasselbe Chat-Template wie bei der Generierung. Schätzen Sie Tokens nicht anhand der Zeichenlänge.
Wo die Dokumentation noch Lücken hat
Ich hätte das hier nicht aufgeschrieben, wenn mich diese Lücken nicht mehrere Tage gekostet hätten.
- Die Beispiele von MLX-Swift hören beim „Hello World“ auf. Alles, was eine App danach für den produktiven Einsatz braucht, bauen Sie selbst: explizites Laden des Modells, RAM-gestaffelte Budgets, die Wahl zwischen Modellwegen und das Wiederherstellen strukturierter Ausgabe.
- Die API der Bibliothek ändert sich. Nach einem Versionssprung lädt man ein Modell anders: Die neuere MLX-Swift-LM-Version erwartet neben dem Verzeichnis auch einen Tokenizer-Loader. Der alte Aufruf mit nur einem Argument ist weg. Das merken Sie erst, wenn der Build fehlschlägt, nicht beim Lesen der Dokumentation.
- Niemand sagt Ihnen, dass ein kleines Modell eine deterministische Reparatur der strukturierten Ausgabe braucht. Ein erneuter Versuch allein reicht nicht. Er ist die naheliegende Idee — und genau die funktioniert nicht.
Das Framework ist gut. Aber was zwischen Beispielcode und produktiver App liegt, ist kaum dokumentiert. Genau diesen Teil hätte ich am Anfang gern gefunden, also habe ich ihn aufgeschrieben.
Wie es weitergeht
Wenn Ihnen solche Praxisnotizen helfen, ist der Newsletter der beste Weg, die nächste nicht zu verpassen.