Pourquoi la première réponse d'Apple Speech n'est pas toujours la meilleure
By Stefan Schmitt · 2026-05-26
Brouillon rédigé avec l'IA ; recherche, édition et vérification des faits par moi — comment j'écris.
Le problème
L'une des sessions de débogage les plus utiles que j'ai eues en construisant Narration Room a commencé par une question faussement simple :
Si le framework Speech d'Apple vous fournit des transcriptions alternatives, pouvez-vous les utiliser pour améliorer la transcription sans demander quoi que ce soit à l'utilisateur ?
Au début, j'avais envie que la réponse soit oui. L'app produisait des erreurs qui semblaient franchement corrigeables. Parfois une phrase apparaissait deux fois. Parfois une expression sortait comme « say a transcript » alors que le contexte rendait « share your transcript » beaucoup plus plausible. Parfois un nom propre était proche, mais faux. Et parfois le résultat en tête n'était qu'un problème de formatage : « 2 day » au lieu de « two-day », « entry level » au lieu de « entry-level », « off trek » au lieu de « off track ».
De l'extérieur, tout cela ressemble au même problème : la transcription est fausse.
Ce n'est pas un seul problème.
Cette distinction a fini par façonner l'implémentation davantage que le reranking lui-même. Les alternatives d'Apple Speech sont utiles, mais elles ne sont pas un moteur de correction générique. Elles sont un ensemble de candidats. Si le bon texte est dans l'ensemble, vous pouvez peut-être le choisir. S'il n'y est pas, vous en êtes réduit à deviner.
Pour une app de capture privée, deviner est précisément la ligne que je ne veux pas franchir.
La mauvaise solution tentante
La solution tentante consiste à faire une passe de post-traitement sur toute la transcription :
- Exécuter la reconnaissance vocale.
- Envoyer la transcription à un LLM.
- Lui demander de nettoyer les noms, la ponctuation, les doublons, la grammaire et les formulations étranges.
- Stocker le résultat nettoyé.
Cela paraît élégant jusqu'au moment où l'on se rappelle à quoi sert l'app. Narration Room peut enregistrer n'importe quoi : notes de réunion, pensées privées, entretien, idée de produit, note juridique, cours, plaisanterie, nom que le modèle n'a jamais vu. Dès que vous laissez un modèle de langage réécrire librement, il rendra parfois le texte plus fluide en le rendant moins fidèle.
C'est peut-être acceptable pour un résumé. Ce ne l'est pas pour la transcription.
J'ai donc resserré le problème :
Pouvons-nous améliorer la transcription d'Apple uniquement en choisissant parmi les alternatives fournies par Apple ?
Cette contrainte est ennuyeuse dans le meilleur sens du terme. Elle signifie que le système peut se tromper, mais qu'il ne peut pas inventer une nouvelle phrase. Si Apple me donne :
0: Then say a transcript or sync it to Narration Room on Mac.
1: Then share your transcript or sync it to Narration Room on Mac.
alors choisir le candidat 1 est une décision de transcription. Mais si Apple ne me donne que la première ligne, la « corriger » en deuxième ligne est une réécriture. Même si cette réécriture me paraît évidente en tant que développeur, elle reste hors de ce que le recognizer a réellement produit.
C'était la ligne que j'ai gardée : choisir uniquement parmi le texte qu'Apple avait déjà produit.
Le modèle mental : une élection, pas une édition
Une fois que j'ai arrêté de penser à cela comme une correction, l'architecture est devenue plus simple.
Mon reranker ne modifie pas le texte. Il organise une élection.
Pour chaque segment final, il reçoit la transcription principale et quelques alternatives. Il les déduplique, écrit une ligne de log, puis pose une seule question : quel candidat est le plus plausible dans le contexte ?
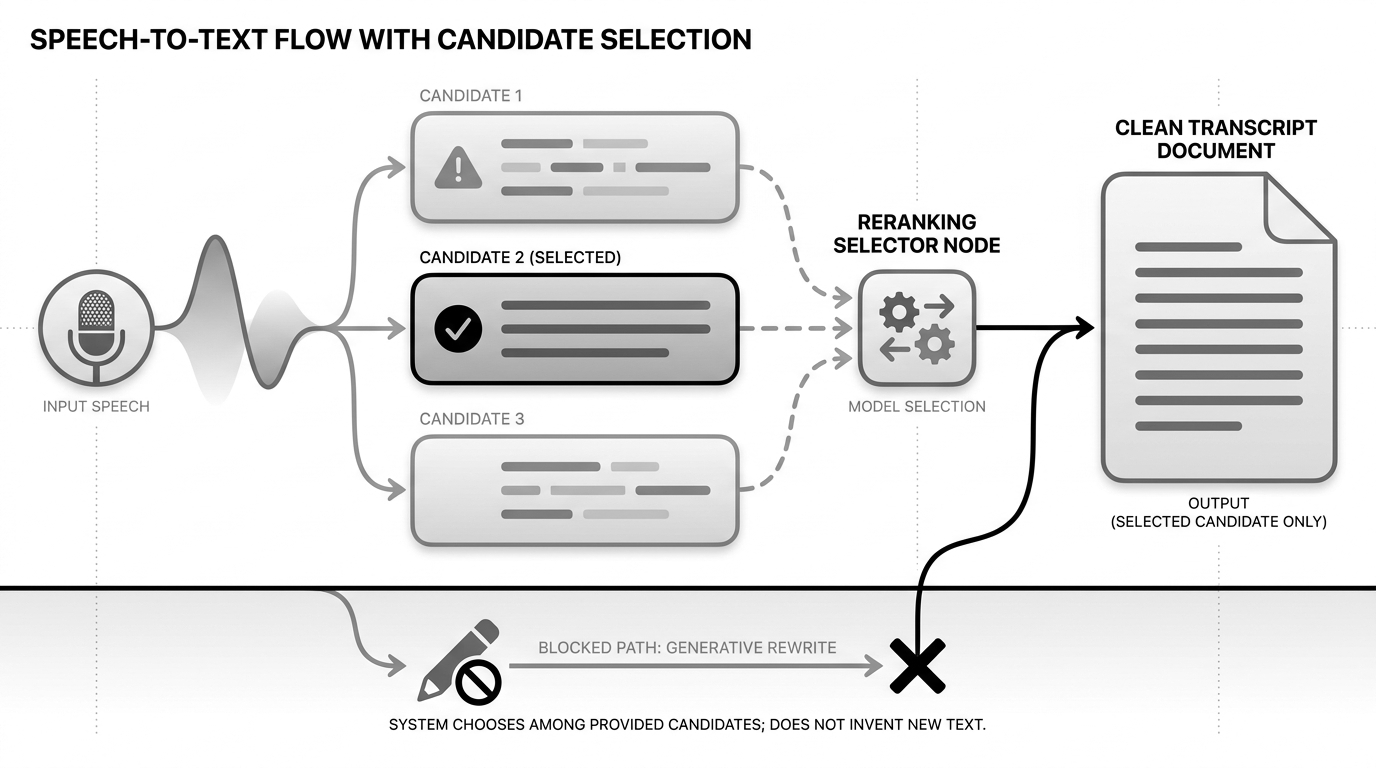
La policy de Narration Room est volontairement petite :
public enum AppleSpeechAlternativeRerankingPolicy: Sendable, Equatable {
case disabled
case conservative
}
Je la garde spécifique à Apple parce que ce comportement appartient au stack Speech d'Apple. Un autre modèle STT peut produire des alternatives avec une sémantique différente, des scores de confiance différents, ou aucune alternative du tout. Si je remplace le recognizer plus tard, je ne veux pas qu'un ensemble d'heuristiques Apple Speech s'exécute silencieusement sur la sortie d'un autre modèle.
L'autre limite que j'ai choisie concerne l'endroit où le reranking peut s'exécuter : uniquement sur les segments finaux de transcription en texte brut.
Il ne s'exécute pas sur les résultats partiels en direct, les sorties avec timestamps de mots, ni les segments avec diarization.
La raison, c'est l'alignement. Dans une transcription en texte brut, remplacer le candidat 0 par le candidat 1 ne change que le texte. Dans une sortie avec timestamps ou diarization, les mots sont liés aux timings et aux segments de locuteur produits par le recognizer. Si je remplace le texte sans reconstruire cette structure, la transcription peut paraître meilleure pendant que les timestamps deviennent faux.
Pourquoi les alternatives déçoivent d'abord
La première surprise a été la fréquence à laquelle les alternatives ne diffèrent pas vraiment.
On s'attend peut-être à une liste comme celle-ci :
0: analyst, as
1: analyst at
2: analyst has
Cela arrive parfois. Le plus souvent, on obtient des variantes de ponctuation :
0: companion.
1: companion,
2: companion?
Ou un bon résultat principal avec de moins bonnes alternatives :
0: ChatGPT
1: chat GPT
Ou, plus frustrant encore, aucune alternative utile. Si le recognizer entend mal un nom de famille et que chaque candidat est une orthographe différente mais fausse, le reranking ne peut pas le réparer sans connaissance externe. Même chose pour un nom de produit, un nom d'entreprise, ou une expression que le modèle acoustique a tout simplement ratée.
Cela a changé ce que j'écrivais dans les logs. J'ai arrêté de ne consigner que le candidat choisi, et j'ai commencé à enregistrer le nombre de candidats, les aperçus et le score de confiance moyen pour chaque segment final. La question n'était plus seulement « est-ce que le reranker a changé le résultat ? ». La meilleure question était : « est-ce qu'Apple nous a seulement donné une option viable ? »
Cette ligne de log est devenue plus utile que prévu. Elle vous dit quelles défaillances relèvent du reranking et lesquelles sont en amont, dans la reconnaissance vocale.
Les règles locales qui valent la peine
Au départ, j'ai voulu utiliser FoundationModels pour toute la décision : lui donner le contexte précédent de la transcription, lui donner les candidats, et lui demander de renvoyer un index.
Cela fonctionne parfois. Mais beaucoup de décisions n'ont pas besoin d'un modèle.
Pour des alternatives équivalentes à l'oral, un sélecteur local déterministe est plus rapide, plus prévisible et plus facile à tester. Si les tokens prononcés sont équivalents, on préfère le candidat avec le meilleur formatage éditorial :
2 day -> two-day
entry level tasks -> entry-level tasks
high level projects -> high-level projects
years experience -> years' experience
AI generated -> AI-generated
Le point essentiel est que mon sélecteur ne réécrit toujours pas. Il ne fait que choisir une alternative déjà fournie par Apple.
La règle de protection est tout aussi importante. « Share cutting » ne doit pas devenir « share-cutting » simplement parce qu'une alternative avec trait d'union existe. Les composés inconnus restent sur le résultat principal, sauf s'ils appartiennent à une petite liste blanche délibérée.
Voilà la forme de la règle :
private static func selectEditorialFormattingAlternative(
from request: AppleSpeechAlternativeChoiceRequest,
topTokens: [String]
) -> Int? {
let topScore = request.candidates[0].text.editorialFormattingScore
for (index, candidate) in request.candidates.enumerated().dropFirst() {
guard candidate.text.spokenComparisonTokens == topTokens else { continue }
guard candidate.text.editorialFormattingScore >= topScore + 3 else { continue }
return index
}
return nil
}
Ce n'est pas malin. C'est précisément l'intérêt. C'est une petite règle avec un blast radius réduit.
La règle d'expression qui semblait presque trop spécifique
Une erreur récurrente était « off trek » quand l'expression attendue était « off track ». Apple fournissait bien « track » comme alternative, mais le modèle continuait de choisir « trek », plus confiant.
Je ne voulais pas d'une règle globale trek -> track. Elle serait fausse dans n'importe quelle note de randonnée.
Le contexte la rend sûre :
private static func isPreferredContextualPhrase(
previousToken: String,
candidateFirstToken: String,
topFirstToken: String
) -> Bool {
switch (previousToken, candidateFirstToken, topFirstToken) {
case ("off", "track", "trek"),
("off", "track", "check"):
true
default:
false
}
}
Cette toute petite règle capture l'expression idiomatique « off track » sans prétendre que « track » est toujours meilleur que « trek ». Elle respecte aussi la même règle de preuve : « track » doit faire partie des candidats d'Apple.
C'est le genre d'heuristique que je suis prêt à livrer. Pas parce qu'elle est sophistiquée, mais parce qu'elle est falsifiable et ciblée.
FoundationModels comme reranker de secours
Pour les cas qui ne sont pas déterministes, j'utilise toujours FoundationModels. La tâche est une classification structurée : choisir un index entier dans une courte liste. J'ai gardé .contentTagging pour cette raison. On ne demande pas au modèle d'écrire de la prose.
Le prompt dit, en substance :
Choose the most plausible speech transcription candidate.
Use only grammar, meaning, nearby transcript context, and confidence.
Prefer the candidate that best continues the previous context.
Use confidence only as a tie-breaker when candidates are equally plausible.
Return only the zero-based integer index.
Do not rewrite text and do not invent a new candidate.
Dans Narration Room, cette deuxième passe est optionnelle. Elle a un timeout. Elle peut ne prendre aucune décision. Elle peut refuser parce que le contexte précédent semble sensible. Elle peut échouer à décoder une réponse structurée.
Ce sont des résultats normaux pour un helper optionnel, pas des raisons de faire échouer la transcription. Si le modèle ne donne pas rapidement une réponse exploitable, Narration Room conserve le résultat en tête d'Apple.
Le cas du refus était le plus intéressant. J'ai vu les guardrails rejeter un contexte de transcription apparemment inoffensif avec « May contain sensitive content ». La bonne correction n'était pas de réduire le use case ou de changer toute l'architecture. C'était de réessayer sans contexte précédent :
do {
return try await generateIndex(prompt: request.prompt)
} catch LanguageModelSession.GenerationError.refusal {
return try? await generateIndex(prompt: request.promptWithoutPreviousContext)
} catch {
return nil
}
Cela donne au modèle une deuxième chance de comparer seulement les candidats. S'il ne peut toujours pas décider, Narration Room garde le résultat principal.
La phrase en double était un autre bug
L'un des premiers échecs ressemblait à du reranking, mais n'en était pas. La transcription répétait une phrase complète deux fois de suite. Mon premier réflexe a été de le traiter comme un problème de correction : peut-être que le modèle pourrait remarquer le doublon et le supprimer.
Mauvaise couche.
Une phrase dupliquée entre deux résultats finaux adjacents n'est pas un problème de reranking. Elle appartient à l'accumulateur, le code qui valide le texte reconnu dans la transcription. Le recognizer peut réviser ou réémettre du texte autour des limites de segment, et l'étape de validation doit gérer cela. Le corriger après coup avec un modèle de langage masquerait le vrai bug et risquerait de supprimer une répétition légitime.
Dans mon code, le nettoyage des doublons vit donc là où le texte est validé dans la transcription, pas dans le reranker. Il ne s'applique qu'au texte brut, pas aux chemins qui exposent le timing des segments. Encore une fois : préserver la structure là où la structure compte.
Cette séparation a immédiatement payé. Le reranker choisit parmi les alternatives. L'accumulateur empêche de valider deux phrases adjacentes identiques. Aucun des deux n'a besoin de prétendre être l'autre.
Les tests qui m'ont donné confiance
Les tests qui m'intéressent le plus sont surtout des tests négatifs. Les tests positifs prouvent le happy path. Les tests négatifs protègent la règle de preuve.
Par exemple, ceci doit changer :
#expect(selected("Villa Villanova", alternatives: ["Villanova"]) == "Villanova")
Mais pas ceci :
#expect(selected("New York", alternatives: ["York"]) == "New York")
Ceci doit changer :
#expect(selected("trek for", alternatives: ["track for"], previousText: "you're off") == "track for")
Mais pas ceci :
#expect(selected("trek", alternatives: ["track"], previousText: "Star") == "trek")
Ces tests encodent mieux la philosophie que n'importe quel commentaire : améliorer la transcription quand la preuve est forte et locale ; sinon ne rien toucher.
Ce que je ne livrerais pas
Je ne livrerais pas une table de substitutions spécifique à l'app pour chaque mauvaise transcription vue pendant les tests. Ce chemin donne l'impression d'avancer pendant une journée, puis devient un piège de maintenance. Aujourd'hui, c'est un nom de famille. Demain, un nom d'entreprise. Puis une ville. Puis un terme technique qui est correct dans l'audio d'un utilisateur et faux dans celui d'un autre.
J'éviterais aussi une passe LLM silencieuse de « transcription propre » sauf si l'UI la présente comme un artefact généré distinct. Une note nettoyée ou un résumé peut être utile. Une transcription doit rester plus proche de l'audio.
Et je ne demanderais pas une interaction utilisateur pour chaque segment ambigu. Cela peut être acceptable dans un éditeur de transcription professionnel, mais ce n'est pas le bon modèle pour un outil de capture. L'app doit prendre des décisions automatiques conservatrices, puis continuer.
Liste de contrôle pour la production
La liste à laquelle j'ai abouti :
- Reranker uniquement les segments finaux de transcription.
- Ignorer le reranking quand des timestamps de mots ou un timing de segment exposé sont demandés.
- Enregistrer le nombre de candidats, l'aperçu et le score de confiance pour chaque segment final avec alternatives.
- Préférer les sélecteurs locaux déterministes avant d'invoquer un modèle de langage.
- Limiter les sélecteurs locaux à des cas précis et tester les cas « ne pas changer ».
- Traiter FoundationModels comme optionnel : timeout, refus, échec de décodage et absence de décision reviennent tous au candidat 0.
- Réessayer FoundationModels sans contexte précédent si les guardrails rejettent le contexte.
- Ne jamais inventer de candidat.
- Garder le nettoyage des phrases dupliquées dans l'accumulateur de validation du texte, pas dans le reranker.
- Rendre la policy désactivable afin de pouvoir couper toute la feature.
Le dernier point compte plus qu'il n'y paraît. La qualité de la reconnaissance vocale est empirique. Je veux un switch que je puisse désactiver si l'heuristique commence à faire du mal.
Là où j'en suis arrivé
Le bon cadrage n'est pas « Est-ce que l'IA peut corriger ma transcription ? »
C'est :
Quand le recognizer est incertain, une deuxième passe peut-elle mieux choisir parmi les signaux que le recognizer a déjà produits ?
C'est une question beaucoup plus petite, et elle mène à un code beaucoup plus sûr.
Je veux toujours une meilleure transcription. Les noms propres restent difficiles. Le vocabulaire de domaine reste difficile. Les limites de segment font encore des choses étranges. Mais la réponse n'est pas de rendre la transcription plus jolie à n'importe quel prix. La réponse est de faire en sorte que chaque couche reste honnête sur ce qu'elle sait.
Apple Speech connaît l'audio et produit des candidats. Mon sélecteur local connaît quelques conventions de formatage. FoundationModels peut parfois juger la grammaire et la continuité. Mon accumulateur sait ce qui a déjà été validé.
Gardez ces rôles séparés, et il devient plus facile de raisonner sur le système.
La suite
Si ce genre de note de terrain vous est utile, la newsletter est le meilleur moyen de ne pas manquer la suivante.