Warum die erste Antwort von Apple Speech nicht immer die beste ist
By Stefan Schmitt · 2026-05-26
Mit KI entworfen; von mir recherchiert, redigiert und auf Fakten geprüft — wie ich schreibe.
Das Problem
Eine der nützlichsten Debugging-Sessions beim Bau von Narration Room begann mit einer scheinbar einfachen Frage:
Wenn Apples Speech-Framework alternative Transkriptionen liefert, können Sie sie nutzen, um die Transkription zu verbessern, ohne den Nutzer zu fragen?
Am Anfang wollte ich, dass die Antwort ja lautet. Die App produzierte Fehler, die sich ärgerlich leicht korrigierbar anfühlten. Manchmal erschien ein Satz zweimal. Manchmal wurde eine Formulierung als „say a transcript“ ausgegeben, obwohl der Kontext „share your transcript“ viel plausibler machte. Manchmal war ein Eigenname nah dran, aber falsch. Und manchmal war das Top-Ergebnis nur ein Formatierungsfehler: „2 day“ statt „two-day“, „entry level“ statt „entry-level“, „off trek“ statt „off track“.
Von außen sieht das alles wie ein einziges Problem aus: Die Transkription ist falsch.
Es ist nicht ein einziges Problem.
Diese Unterscheidung hat die Implementierung stärker geprägt als das Reranking selbst. Apple Speech-Alternativen sind nützlich, aber sie sind keine allgemeine Korrektur-Engine. Sie sind eine Kandidatenmenge. Wenn der richtige Text in dieser Menge steckt, können Sie ihn vielleicht auswählen. Wenn er nicht darin steckt, raten Sie.
Für eine private Capture-App ist Raten genau die Grenze, die ich nicht überschreiten will.
Die verlockende falsche Lösung
Die verlockende Lösung ist ein Post-Processing-Lauf über die gesamte Transkription:
- Spracherkennung ausführen.
- Die Transkription an ein LLM schicken.
- Es bitten, Namen, Zeichensetzung, Duplikate, Grammatik und seltsame Formulierungen aufzuräumen.
- Das bereinigte Ergebnis speichern.
Das klingt elegant, bis Sie sich daran erinnern, wofür die App gedacht ist. Narration Room kann alles Mögliche aufnehmen: Meeting-Notizen, private Gedanken, ein Interview, eine Produktidee, eine juristische Notiz, eine Vorlesung, einen Witz, einen Namen, den das Modell noch nie gesehen hat. Sobald Sie ein Sprachmodell frei umschreiben lassen, macht es den Text manchmal flüssiger, indem es ihn weniger wahrheitsgetreu macht.
Für eine Zusammenfassung kann das akzeptabel sein. Für die Transkription ist es das nicht.
Also habe ich das Problem enger gefasst:
Können wir Apples Transkription nur dadurch verbessern, dass wir unter den von Apple bereitgestellten Alternativen wählen?
Diese Einschränkung ist auf die beste Art langweilig. Sie bedeutet, dass das System falsch liegen kann, aber keinen neuen Satz erfinden kann. Wenn Apple mir Folgendes gibt:
0: Then say a transcript or sync it to Narration Room on Mac.
1: Then share your transcript or sync it to Narration Room on Mac.
dann ist die Auswahl von Kandidat 1 eine Transkriptionsentscheidung. Wenn Apple mir aber nur die erste Zeile gibt, ist die „Korrektur“ zur zweiten Zeile eine Umschreibung. Selbst wenn mir diese Umschreibung als Entwickler offensichtlich erscheint, liegt sie außerhalb dessen, was der Recognizer tatsächlich geliefert hat.
Das war die Linie, an die ich mich gehalten habe: nur unter Text wählen, den Apple bereits geliefert hat.
Das mentale Modell: Wahl, nicht Bearbeitung
Als ich aufgehört habe, das als Korrektur zu sehen, wurde die Architektur einfacher.
Mein Reranker bearbeitet keinen Text. Er hält eine Wahl ab.
Für jedes finale Segment erhält er die Top-Transkription und einige Alternativen. Er dedupliziert und loggt sie und stellt eine Frage: Welcher Kandidat ist im Kontext am plausibelsten?
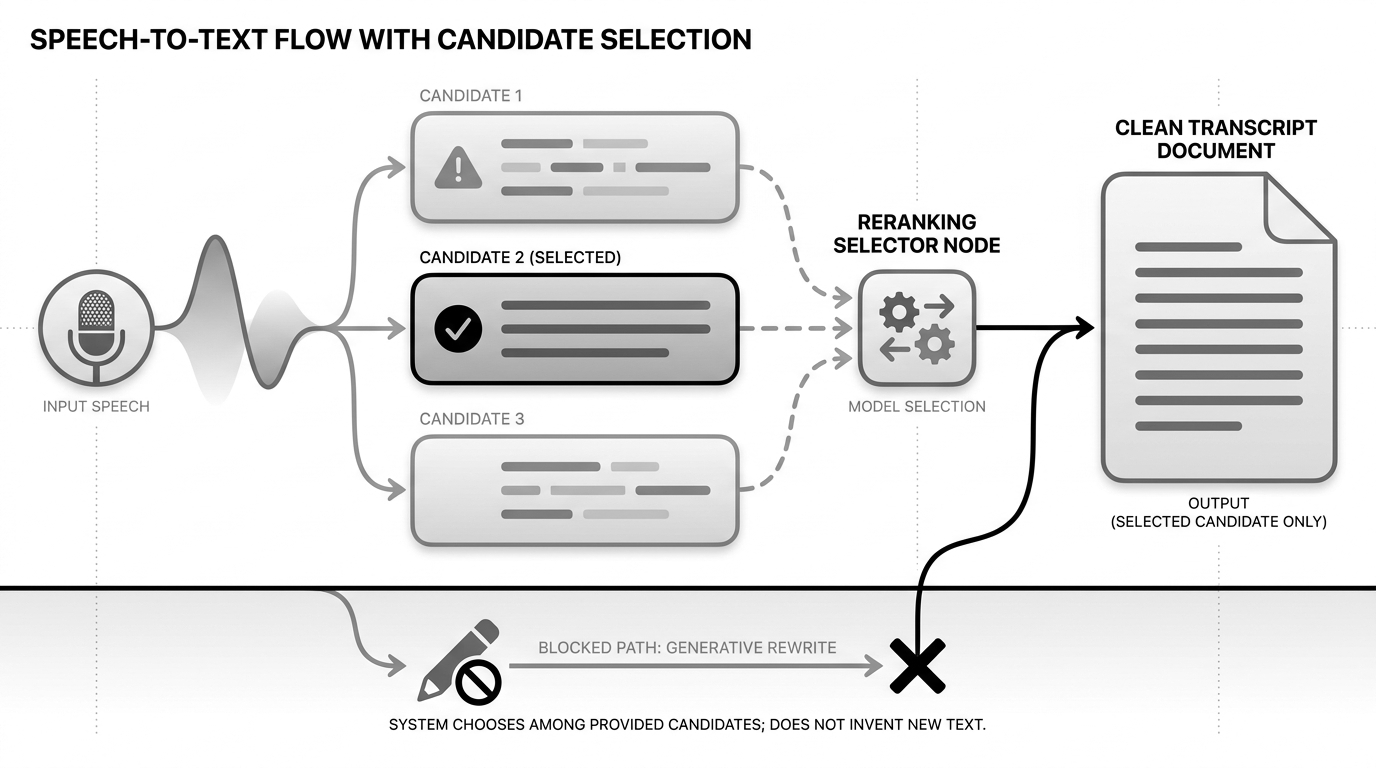
Die Policy von Narration Room ist absichtlich klein:
public enum AppleSpeechAlternativeRerankingPolicy: Sendable, Equatable {
case disabled
case conservative
}
Ich halte sie Apple-spezifisch, weil dieses Verhalten zu Apples Speech-Stack gehört. Ein anderes STT-Modell kann Alternativen mit anderer Semantik liefern, andere Confidence-Werte haben oder gar keine Alternativen ausgeben. Wenn ich später den Recognizer austausche, möchte ich nicht, dass eine ganze Reihe von Apple Speech-Heuristiken unbemerkt auf der Ausgabe eines anderen Modells läuft.
Die andere Grenze, die ich gewählt habe, betrifft den Ort, an dem Reranking laufen darf: nur auf finalen Plain-Text-Segmenten der Transkription.
Es läuft nicht auf Live-Partials, Ausgaben mit Word Timestamps oder Segmenten mit Diarization.
Der Grund ist die Zuordnung der Wörter zu Timings. In einer Plain-Text-Transkription ändert der Wechsel von Kandidat 0 zu Kandidat 1 nur den Text. In Ausgaben mit Timestamps oder Diarization sind die Wörter an Timings und Sprechersegmente des Recognizers gebunden. Wenn ich den Text austausche, ohne diese Struktur neu aufzubauen, kann die Transkription sauberer wirken, während die Timings falsch werden.
Warum Alternativen zuerst enttäuschen
Die erste Überraschung war, wie oft Alternativen nicht wirklich unterschiedlich sind.
Man erwartet vielleicht eine Liste wie diese:
0: analyst, as
1: analyst at
2: analyst has
Manchmal bekommt man so etwas. Häufiger bekommt man Zeichensetzungsvarianten:
0: companion.
1: companion,
2: companion?
Oder ein korrektes Top-Ergebnis mit schlechteren Alternativen:
0: ChatGPT
1: chat GPT
Oder, frustrierender, gar keine nützliche Alternative. Wenn der Recognizer einen Nachnamen falsch hört und jeder Kandidat eine andere falsche Schreibweise ist, kann Reranking das nicht ohne externes Wissen reparieren. Dasselbe gilt für einen Produktnamen, einen Firmennamen oder eine Formulierung, die das akustische Modell schlicht verpasst hat.
Das hat verändert, was ich logge. Ich habe aufgehört, nur den ausgewählten Kandidaten zu loggen, und angefangen, Kandidatenanzahl, Vorschau und durchschnittlichen Confidence-Score für jedes finale Segment zu erfassen. Die Frage war nicht nur: „Hat der Reranker das Ergebnis verändert?“ Die bessere Frage war: „Hat Apple uns überhaupt eine brauchbare Option gegeben?“
Diese Log-Zeile wurde nützlicher, als ich erwartet hatte. Sie sagt Ihnen, welche Fehler zum Reranking gehören und welche upstream in der Spracherkennung liegen.
Die lokalen Regeln, die sich lohnen
Ursprünglich wollte ich FoundationModels die ganze Entscheidung überlassen: vorherigen Transkriptionskontext geben, Kandidaten geben, Index zurückgeben lassen.
Das funktioniert manchmal. Aber viele Entscheidungen brauchen kein Modell.
Für Alternativen, die gesprochen gleichwertig sind, ist ein deterministischer lokaler Selektor schneller, vorhersehbarer und leichter zu testen. Wenn die gesprochenen Tokens äquivalent sind, bevorzuge den Kandidaten mit besserer redaktioneller Formatierung:
2 day -> two-day
entry level tasks -> entry-level tasks
high level projects -> high-level projects
years experience -> years' experience
AI generated -> AI-generated
Entscheidend ist, dass mein Selektor weiterhin nicht umschreibt. Er wählt nur eine Alternative, die Apple bereits geliefert hat.
Die Schutzregel ist genauso wichtig. „Share cutting“ soll nicht zu „share-cutting“ werden, nur weil eine Alternative mit Bindestrich existiert. Unbekannte Zusammensetzungen bleiben beim Top-Ergebnis, außer sie stehen auf einer kleinen, bewusst gepflegten Whitelist.
So sieht die Regel aus:
private static func selectEditorialFormattingAlternative(
from request: AppleSpeechAlternativeChoiceRequest,
topTokens: [String]
) -> Int? {
let topScore = request.candidates[0].text.editorialFormattingScore
for (index, candidate) in request.candidates.enumerated().dropFirst() {
guard candidate.text.spokenComparisonTokens == topTokens else { continue }
guard candidate.text.editorialFormattingScore >= topScore + 3 else { continue }
return index
}
return nil
}
Das ist nicht clever. Genau das ist der Punkt. Es ist eine kleine Regel mit kleinem Blast Radius.
Die Phrasenregel, die fast zu spezifisch wirkte
Ein wiederkehrender Fehler war „off trek“, wenn die gemeinte Phrase „off track“ war. Apple lieferte „track“ tatsächlich als Alternative, aber das Modell wählte weiter „trek“ mit höherer Confidence.
Ich wollte keine globale Regel trek -> track. Die wäre in jeder Wandernotiz falsch.
Der Kontext macht sie sicher:
private static func isPreferredContextualPhrase(
previousToken: String,
candidateFirstToken: String,
topFirstToken: String
) -> Bool {
switch (previousToken, candidateFirstToken, topFirstToken) {
case ("off", "track", "trek"),
("off", "track", "check"):
true
default:
false
}
}
Diese winzige Regel erkennt die Redewendung „off track“, ohne zu behaupten, dass „track“ immer besser ist als „trek“. Sie hält außerdem dieselbe Beweisregel ein: „track“ muss einer von Apples Kandidaten sein.
Das ist die Art Heuristik, die ich bereit bin zu shippen. Nicht weil sie ausgefeilt ist, sondern weil sie falsifizierbar und eng ist.
FoundationModels als Fallback-Reranker
Für Fälle, die nicht deterministisch sind, verwende ich weiterhin FoundationModels. Die Aufgabe ist strukturierte Klassifikation: einen Integer-Index aus einer kurzen Liste auswählen. Deshalb habe ich .contentTagging beibehalten. Das Modell soll keine Prosa schreiben.
Der Prompt sagt im Kern:
Choose the most plausible speech transcription candidate.
Use only grammar, meaning, nearby transcript context, and confidence.
Prefer the candidate that best continues the previous context.
Use confidence only as a tie-breaker when candidates are equally plausible.
Return only the zero-based integer index.
Do not rewrite text and do not invent a new candidate.
In Narration Room ist dieser zweite Lauf optional. Er hat einen Timeout. Er kann keine Entscheidung treffen. Er kann ablehnen, weil der vorherige Kontext sensibel wirkt. Er kann daran scheitern, eine strukturierte Antwort zu dekodieren.
Das sind normale Ergebnisse für einen optionalen Helfer, keine Gründe, die Transkription fehlschlagen zu lassen. Wenn das Modell nicht schnell eine brauchbare Antwort liefert, behält Narration Room Apples Top-Ergebnis.
Der Refusal-Fall war der interessanteste. Ich sah Guardrails harmlos wirkenden Transkriptionskontext mit „May contain sensitive content“ ablehnen. Die Lösung war nicht, den Use Case zu schwächen oder die ganze Architektur zu ändern. Die Lösung war, es ohne vorherigen Kontext erneut zu versuchen:
do {
return try await generateIndex(prompt: request.prompt)
} catch LanguageModelSession.GenerationError.refusal {
return try? await generateIndex(prompt: request.promptWithoutPreviousContext)
} catch {
return nil
}
Damit bekommt das Modell eine zweite Chance, nur die Kandidaten zu vergleichen. Wenn es immer noch nicht entscheiden kann, behält Narration Room das Top-Ergebnis.
Der doppelte Satz war ein anderer Bug
Einer der frühen Fehler sah nach Reranking aus, war aber keiner. Die Transkription wiederholte einen vollständigen Satz direkt hintereinander. Mein erster Impuls war, es als Korrekturproblem zu behandeln: Vielleicht könnte das Modell das Duplikat bemerken und entfernen.
Falscher Layer.
Ein doppelter Satz über benachbarte finale Ausgaben hinweg ist kein Reranking-Problem. Er gehört in den Akkumulator, den Code, der erkannten Text in die Transkription übernimmt. Der Recognizer kann Text an Segmentgrenzen überarbeiten oder erneut ausgeben, und dieser Übernahmeschritt muss damit umgehen. Das nachträglich mit einem Sprachmodell zu korrigieren, würde den echten Bug verdecken und riskieren, legitime Wiederholung zu löschen.
In meinem Code lebt die Duplikatbereinigung deshalb dort, wo Text in die Transkription übernommen wird, nicht im Reranker. Sie gilt nur für Plain Text, nicht für Pfade, die Segment-Timing offenlegen. Wieder: Struktur erhalten, wo Struktur zählt.
Diese Trennung hat sich sofort ausgezahlt. Der Reranker wählt unter Alternativen. Der Akkumulator verhindert das Übernehmen benachbarter doppelter Sätze. Keiner der beiden muss so tun, als wäre er der andere.
Die Tests, die mir Vertrauen gegeben haben
Die Tests, die mir wichtig sind, sind vor allem negative Tests. Positive Tests beweisen den Happy Path. Negative Tests schützen die Beweisregel.
Zum Beispiel sollte sich das hier ändern:
#expect(selected("Villa Villanova", alternatives: ["Villanova"]) == "Villanova")
Aber das hier nicht:
#expect(selected("New York", alternatives: ["York"]) == "New York")
Das hier sollte sich ändern:
#expect(selected("trek for", alternatives: ["track for"], previousText: "you're off") == "track for")
Aber das hier nicht:
#expect(selected("trek", alternatives: ["track"], previousText: "Star") == "trek")
Diese Tests kodieren die Philosophie besser als jeder Kommentar: die Transkription verbessern, wenn das Signal stark und lokal ist; sonst nichts anfassen.
Was ich nicht shippen würde
Ich würde kein app-spezifisches Phrasen-Mapping für jede schlechte Transkription shippen, die ich beim Testen sehe. Dieser Weg fühlt sich einen Tag lang produktiv an und wird dann zur Wartungsfalle. Heute ist es ein Nachname. Morgen ein Firmenname. Dann eine Stadt. Dann ein technischer Begriff, der im Audio eines Nutzers richtig und im Audio eines anderen falsch ist.
Ich würde außerdem keinen stillen LLM-Lauf für eine „bereinigte Transkription“ verwenden, außer die UI kennzeichnet sie als separates generiertes Artefakt. Eine aufgeräumte Notiz oder Zusammenfassung kann nützlich sein. Eine Transkription sollte näher am Audio bleiben.
Und ich würde keine Nutzerinteraktion für jedes mehrdeutige Segment verlangen. In einem professionellen Transkriptionseditor kann das akzeptabel sein, aber für ein Capture-Tool ist es das falsche Modell. Die App sollte konservative automatische Entscheidungen treffen und weiterlaufen.
Produktions-Checkliste
Die Checkliste, bei der ich gelandet bin:
- Nur finale Transkriptionssegmente reranken.
- Reranking überspringen, wenn Word Timestamps oder offengelegtes Segment-Timing angefordert sind.
- Kandidatenanzahl, Vorschau und Confidence für jedes finale Segment mit Alternativen loggen.
- Deterministische lokale Selektoren bevorzugen, bevor ein Sprachmodell aufgerufen wird.
- Lokale Selektoren eng halten und die „nicht ändern“-Fälle testen.
- FoundationModels als optional behandeln: Timeout, Refusal, Dekodierungsfehler und keine Entscheidung fallen alle auf Kandidat 0 zurück.
- FoundationModels ohne vorherigen Kontext erneut versuchen, wenn Guardrails den Kontext ablehnen.
- Niemals einen Kandidaten erfinden.
- Duplikatbereinigung im Textübernahme-Akkumulator halten, nicht im Reranker.
- Die Policy abschaltbar machen, damit das ganze Feature deaktiviert werden kann.
Der letzte Punkt ist wichtiger, als er klingt. Sprachqualität ist empirisch. Ich will einen Schalter, den ich umlegen kann, wenn die Heuristik Schaden anrichtet.
Wo ich gelandet bin
Das nützliche Framing ist nicht: „Kann KI meine Transkription korrigieren?“
Sondern:
Wenn der Recognizer unsicher ist, kann ein zweiter Lauf aus seinen vorhandenen Kandidaten die bessere Option wählen?
Das ist eine viel kleinere Frage, und sie führt zu deutlich sichererem Code.
Ich will weiterhin bessere Transkription. Eigennamen bleiben schwierig. Domänenvokabular bleibt schwierig. Segmentgrenzen verhalten sich weiterhin seltsam. Aber die Antwort ist nicht, die Transkription um jeden Preis hübscher zu machen. Die Antwort ist, dafür zu sorgen, dass jeder Layer ehrlich bei dem bleibt, was er weiß.
Apple Speech kennt das Audio und erzeugt Kandidaten. Mein lokaler Selektor kennt ein paar Formatierungskonventionen. FoundationModels kann manchmal Grammatik und Kontinuität beurteilen. Mein Akkumulator weiß, was bereits übernommen wurde.
Halten Sie diese Aufgaben getrennt, und das System wird leichter nachvollziehbar.
Wie es weitergeht
Wenn Ihnen solche Praxisnotizen helfen, ist der Newsletter der beste Weg, die nächste nicht zu verpassen.