Why Apple Speech's first answer isn't always its best
By Stefan Schmitt · 2026-05-26
Drafted with AI; researched, edited, and fact-checked by me — how I write.
The problem
One of the more useful debugging sessions I had while building Narration Room started with a deceptively simple question:
If Apple's Speech framework gives you alternative transcriptions, can you use them to make the transcript better without asking the user?
At first I wanted the answer to be yes. The app was producing errors that felt annoyingly fixable. Sometimes a sentence appeared twice. Sometimes a phrase came out as "say a transcript" when the surrounding context made "share your transcript" much more plausible. Sometimes a proper noun was close but wrong. And sometimes the top result was just a formatting miss: "2 day" instead of "two-day", "entry level" instead of "entry-level", "off trek" instead of "off track".
Those all look like one problem from the outside: the transcript is wrong.
They are not one problem.
That distinction ended up shaping the implementation more than the reranking itself. Apple Speech alternatives are useful, but they are not a general correction engine. They are a candidate set. If the right text is in the set, you may be able to choose it. If it is not in the set, you are guessing.
For a private capture app, guessing is the line I do not want to cross.
The tempting wrong solution
The tempting solution is a post-processing pass over the whole transcript:
- Run speech recognition.
- Send the transcript to an LLM.
- Ask it to clean up names, punctuation, duplicates, grammar, and strange phrases.
- Store the cleaned result.
That sounds elegant until you remember what the app is for. Narration Room can record anything: meeting notes, private thoughts, an interview, a product idea, a legal note, a lecture, a joke, a name the model has never seen. The moment you let a language model rewrite freely, it will sometimes make the text more fluent by making it less true.
That might be acceptable for a summary. It is not acceptable for the transcript.
So I narrowed the problem:
Can we improve Apple's transcript only by choosing among Apple-provided alternatives?
That constraint is boring in the best way. It means the system can be wrong, but it cannot invent a new sentence. If Apple gives me:
0: Then say a transcript or sync it to Narration Room on Mac.
1: Then share your transcript or sync it to Narration Room on Mac.
then selecting candidate 1 is a transcription decision. But if Apple only gives me the first line, "fixing" it to the second line is a rewrite. Even if the rewrite is obvious to me as the developer, it is still outside the evidence the recognizer produced.
That was the line I kept: choose only among text Apple already produced.
The mental model: election, not editing
Once I stopped thinking about this as correction, the architecture became simpler.
My reranker does not edit text. It holds an election.
For each final segment, it receives the top transcript and a few alternatives. It deduplicates them, logs them, and asks one question: which candidate is most plausible in context?
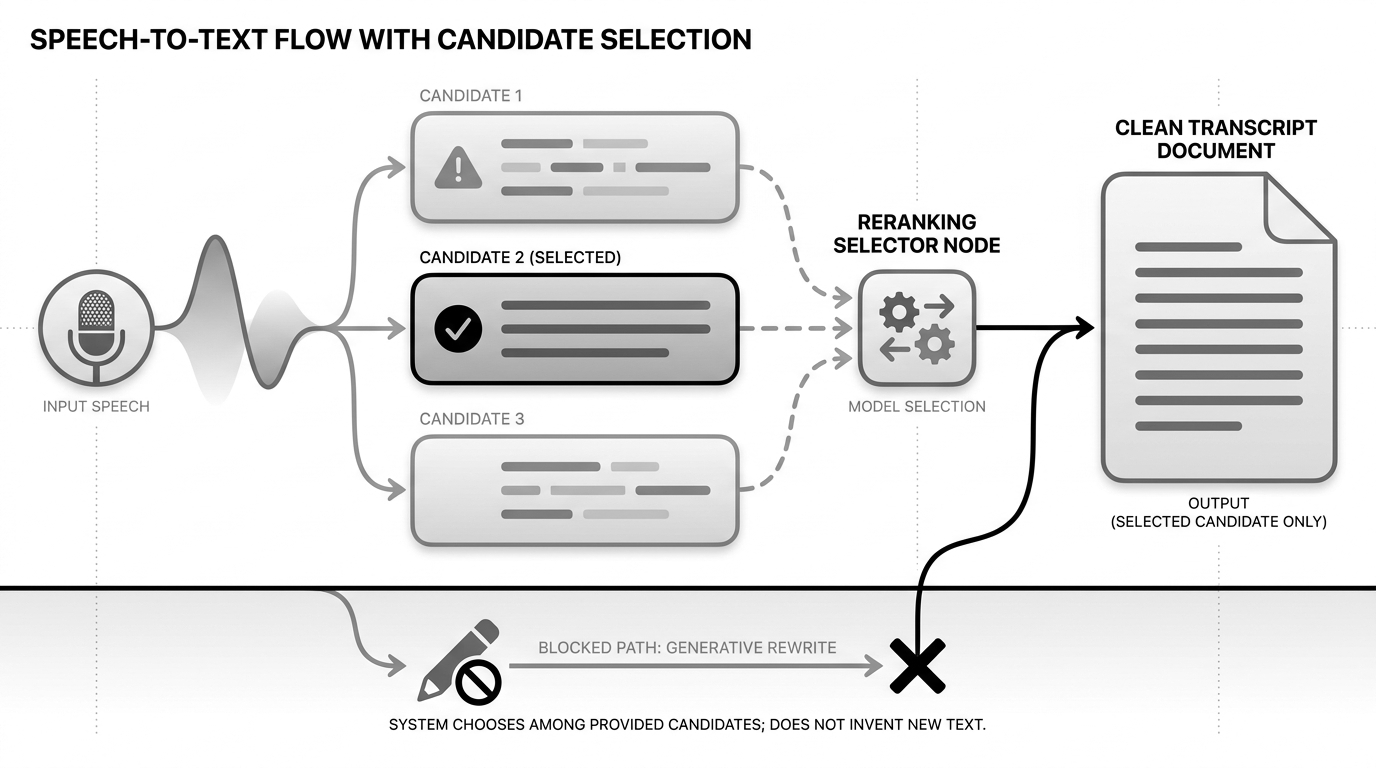
The Narration Room policy is deliberately small:
public enum AppleSpeechAlternativeRerankingPolicy: Sendable, Equatable {
case disabled
case conservative
}
I keep it Apple-specific because this behavior belongs to Apple's speech stack. A different STT model may produce alternatives with different semantics, confidence behavior, or no alternatives at all. If I swap recognizers later, I do not want a pile of Apple Speech heuristics silently running on a different model's output.
The other limit I chose is about where reranking may run: only on final plain-text transcript segments.
It does not run on live partial results, word-timestamp output, or diarized segments.
The reason is alignment. In a plain transcript, changing candidate 0 to candidate 1 only changes text. In timestamped or diarized output, the words are tied to timings and speaker segments from the recognizer. If I swap the text without rebuilding that structure, the transcript can look cleaner while the timings become wrong.
Why alternatives disappoint at first
The first surprise was how often alternatives are not meaningfully different.
You might expect a list like this:
0: analyst, as
1: analyst at
2: analyst has
Sometimes you get that. More often you get punctuation variants:
0: companion.
1: companion,
2: companion?
Or a correct top result plus worse alternatives:
0: ChatGPT
1: chat GPT
Or, more frustratingly, no useful alternative at all. If the recognizer hears a surname incorrectly and every candidate is a different wrong spelling, reranking cannot repair it without external knowledge. The same goes for a product name, a company name, or a phrase the acoustic model simply missed.
That changed what I logged. I stopped only logging the selected candidate and started logging the candidate count, previews, and average confidence for every final segment. The point was not just "did the reranker change the result?" The better question was: "Did Apple even give us a viable option?"
That log line became more useful than I expected. It tells you which failures belong to reranking and which belong upstream in recognition.
The local rules that are worth having
I originally reached for FoundationModels for the whole decision: give it the previous transcript context, give it the candidates, ask it to return an index.
That works sometimes. But a lot of decisions do not need a model.
For formatting-equivalent alternatives, a deterministic local selector is faster, more predictable, and easier to test. If the spoken tokens are equivalent, prefer the candidate with better editorial formatting:
2 day -> two-day
entry level tasks -> entry-level tasks
high level projects -> high-level projects
years experience -> years' experience
AI generated -> AI-generated
The key is that my selector still does not rewrite. It only chooses an alternative Apple already provided.
The guardrail is equally important. "Share cutting" should not become "share-cutting" just because a hyphenated alternative exists. Unknown compounds stay with the top result unless they are on a small, deliberate whitelist.
That is the shape of the rule:
private static func selectEditorialFormattingAlternative(
from request: AppleSpeechAlternativeChoiceRequest,
topTokens: [String]
) -> Int? {
let topScore = request.candidates[0].text.editorialFormattingScore
for (index, candidate) in request.candidates.enumerated().dropFirst() {
guard candidate.text.spokenComparisonTokens == topTokens else { continue }
guard candidate.text.editorialFormattingScore >= topScore + 3 else { continue }
return index
}
return nil
}
This is not clever. That is the point. It is a small rule with a small blast radius.
The phrase rule that almost felt too specific
One repeated error was "off trek" when the intended phrase was "off track". Apple did provide "track" as an alternative, but the model kept choosing the higher-confidence "trek".
I did not want a global trek -> track rule. That would be wrong in any hiking note.
The context makes it safe:
private static func isPreferredContextualPhrase(
previousToken: String,
candidateFirstToken: String,
topFirstToken: String
) -> Bool {
switch (previousToken, candidateFirstToken, topFirstToken) {
case ("off", "track", "trek"),
("off", "track", "check"):
true
default:
false
}
}
That tiny rule captures the idiom "off track" without claiming that "track" is always better than "trek". It also keeps the same evidence rule: "track" must be one of Apple's candidates.
This is the kind of heuristic I am willing to ship. Not because it is sophisticated, but because it is falsifiable and narrow.
FoundationModels as a fallback reranker
For the cases that are not deterministic, I still use FoundationModels. The task is structured classification: choose one integer index from a short list. I kept .contentTagging for that reason. The model is not asked to write prose.
The prompt says, in effect:
Choose the most plausible speech transcription candidate.
Use only grammar, meaning, nearby transcript context, and confidence.
Prefer the candidate that best continues the previous context.
Use confidence only as a tie-breaker when candidates are equally plausible.
Return only the zero-based integer index.
Do not rewrite text and do not invent a new candidate.
In Narration Room, that second pass is optional. It has a timeout. It can return no decision. It can refuse because the previous context looks sensitive. It can fail to decode a structured response.
Those are normal outcomes for an optional helper, not reasons to fail the transcript. If the model does not give a usable answer quickly, Narration Room keeps Apple's top result.
The refusal case was the most interesting. I saw guardrails reject harmless-looking transcript context with "May contain sensitive content." The fix was not to weaken the use case or change the whole architecture. It was to retry without previous context:
do {
return try await generateIndex(prompt: request.prompt)
} catch LanguageModelSession.GenerationError.refusal {
return try? await generateIndex(prompt: request.promptWithoutPreviousContext)
} catch {
return nil
}
That gives the model a second chance to compare only the candidates. If it still cannot decide, Narration Room keeps the top result.
The duplicate sentence was a different bug
One of the early failures looked like reranking but was not. The transcript repeated a full sentence back-to-back. My first instinct was to treat it as a correction problem: maybe the model could notice the duplicate and remove it.
Wrong layer.
A duplicate sentence across adjacent final emissions is not a reranking problem. It belongs in the accumulator, the code that commits recognized text to the transcript. The recognizer can revise or re-emit text around segment boundaries, and the commit step has to handle that. Fixing it after the fact with a language model would hide the real bug and risk deleting legitimate repetition.
So in my code, duplicate cleanup lives where text is committed to the transcript, not in the reranker. It only applies to plain transcript text, not paths that expose segment timing. Again: preserve structure where structure matters.
That separation paid off immediately. The reranker chooses among alternatives. The accumulator prevents adjacent duplicate sentence commits. Neither has to pretend to be the other.
Tests that made me trust the feature
The tests I care about are mostly negative tests. Positive tests prove the happy path. Negative tests protect the evidence rule.
For example, this should change:
#expect(selected("Villa Villanova", alternatives: ["Villanova"]) == "Villanova")
But this should not:
#expect(selected("New York", alternatives: ["York"]) == "New York")
This should change:
#expect(selected("trek for", alternatives: ["track for"], previousText: "you're off") == "track for")
But this should not:
#expect(selected("trek", alternatives: ["track"], previousText: "Star") == "trek")
Those tests encode the philosophy better than any comment: improve the transcript when the evidence is strong and local; otherwise leave it alone.
What I would not ship
I would not ship an app-specific phrase map for every bad transcript I see during testing. That path feels productive for a day and then turns into a maintenance trap. Today it is one surname. Tomorrow it is a company name. Then a city. Then a technical term that is right in one user's audio and wrong in another's.
I would also avoid a silent "clean transcript" LLM pass unless the UI labels it as a separate generated artifact. A cleaned-up note or summary can be useful. A transcript should stay closer to the audio.
And I would not require user interaction for every ambiguous segment. That may be acceptable in a professional transcription editor, but it is wrong for a capture tool. The app should make conservative automatic decisions and move on.
Production checklist
The checklist I ended up with:
- Rerank only final transcript segments.
- Skip reranking when word timestamps or exposed segment timing are requested.
- Log candidate count, preview, and confidence for every final segment with alternatives.
- Prefer deterministic local selectors before invoking a language model.
- Keep local selectors narrow and test the "do not change" cases.
- Treat FoundationModels as optional: timeout, refusal, decoding failure, and no decision all fall back to candidate 0.
- Retry FoundationModels without previous context if guardrails reject the context.
- Never invent a candidate.
- Keep duplicate sentence cleanup in the text-commit accumulator, not the reranker.
- Make the policy switchable so the whole feature can be disabled.
The last point matters more than it sounds. Speech quality is empirical. I want a switch I can turn off if the heuristic starts doing harm.
Where I landed
The useful framing is not "Can AI fix my transcript?"
It is:
When the recognizer is uncertain, can a second pass choose better among the evidence the recognizer already produced?
That is a much smaller question, and it leads to much safer code.
I still want better transcription. Proper nouns remain hard. Domain vocabulary remains hard. Segment boundaries still do strange things. But the answer is not to make the transcript prettier at any cost. The answer is to make each layer honest about what it knows.
Apple Speech knows the audio and produces candidates. My local selector knows a few formatting conventions. FoundationModels can sometimes judge grammar and continuity. My accumulator knows what has already been committed.
Keep those jobs separate, and the system becomes easier to reason about.
What's next
If this kind of field note is useful, the newsletter is the best way to catch the next one.